|
I am currently a Senior Researcher at Visual Generation Group (a.k.a. Kling Team), Kuaishou Technology. I obtained my Ph.D. from MMLab of the Chinese University of Hong Kong, advised by Prof. Hongsheng Li. Prior to this, I obtained Bachelor of Engineer & Bachelor of Science degrees from Zhejiang University and Simon Fraser University, respectively. I'm interested in topics related to video generation. We are actively looking for research interns to work on cutting-edge research topics. Feel free to email me if you are interested. |

|
|
|
* denotes first-author. † denotes corresponding author or project leader. Representative papers are highlighted. |
|
Yawen Luo, Jianhong Bai, Xiaoyu Shi†, Menghan Xia, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, Tianfan Xue† Siggraph Asia, 2025 Paper / Project page A framework that enables users to replicate camera movements from reference videos without requiring camera parameters or test-time fine-tuning. |
|
|
Qinghe Wang*, Yawen Luo*, Xiaoyu Shi†, Xu Jia†, Huchuan Lu, Tianfan Xue†, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai Siggraph, 2025 Paper / Project page A 3D-aware and controllable text-to-video generation method allows users to manipulate objects and camera jointly in 3D space for high-quality cinematic video creation. |
|
|
Xiaoyu Shi, Zhaoyang Huang, Fu-Yun, Wang, Weikang Bian, Dasong Li, Yi Zhang, Manyuan Zhang, Kachun Cheung, Simon See, Hongwei Qin, Jifeng Dai, Hongsheng Li Siggraph, 2024 Paper / Project page / Code We introduce Motion-I2V, a novel framework for consistent and controllable image-to-video generation (I2V). In contrast to previous methods that directly learn the complicated image-to-video mapping, Motion-I2V factorizes I2V into two stages with explicit motion modeling. |
|
|
Weikang Bian*, Zhaoyang Huang*, Xiaoyu Shi, Yitong Dong, Yijin Li, Hongsheng Li NeurIPS, 2023 Project page / Paper We set new SOTA on the task of Tracking Any Point (TAP) by introducing rich spatial context features. |
|
|
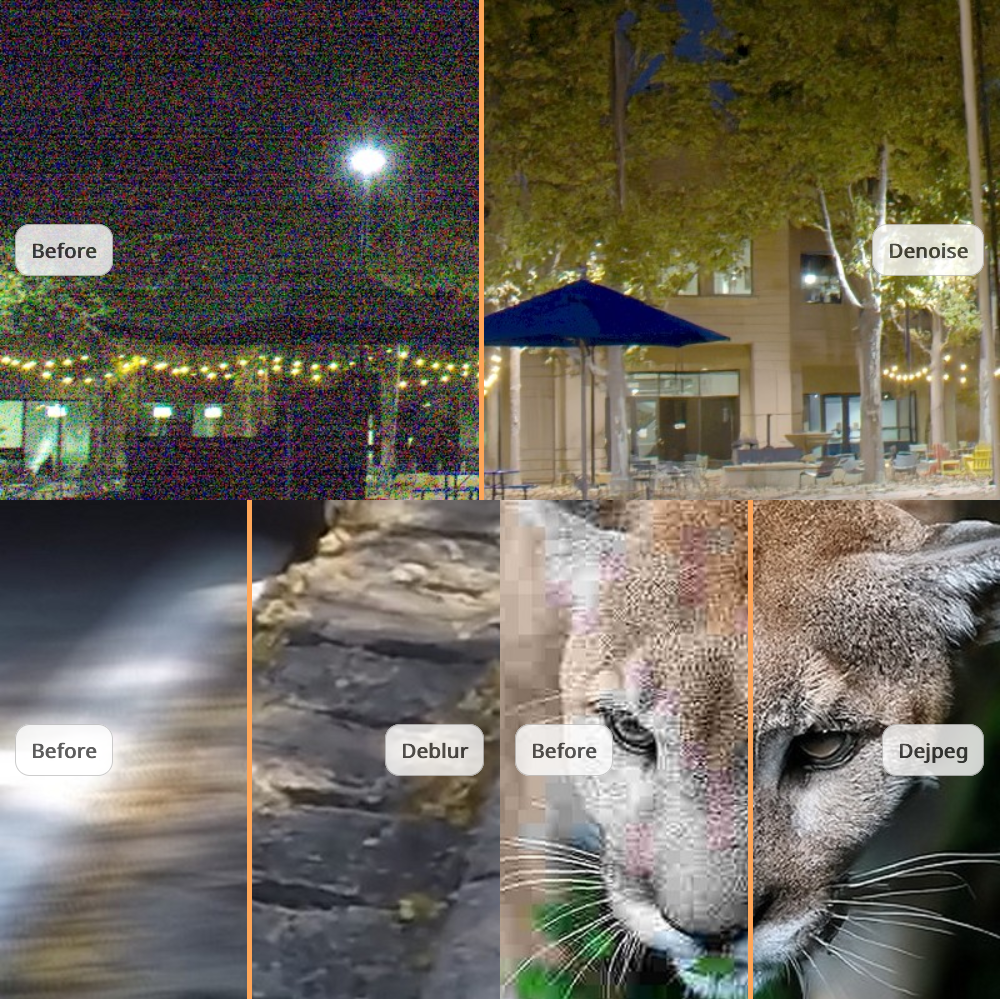
Yi Zhang, Xiaoyu Shi, Dasong Li, Xiaogang Wang, Hongsheng Li NeurIPS, 2023 Project page / Paper / Code A unified conditional framework based on diffusion models for image restoration. |
|
Xiaoyu Shi, Zhaoyang Huang, Weikang Bian, Dasong Li, Manyuan Zhang, Kachun Cheung, Simon See, Hongwei Qin, Jifeng Dai, Hongsheng Li ICCV, 2023 Paper / Code First method to achieve sub-pixel accuracy on the Sintel benchmark. 19.2% error reduction from the best published result on the KITTI-2015 benchmark. |
|
|
Yijin Li, Zhaoyang Huang, Shuo Chen, Xiaoyu Shi, Hongsheng Li, Hujun Bao, Zhaopeng Cui, Guofeng Zhang IROS, 2023 Paper We build a benchmark BlinkFlow for training and evaluating event-based optical flow estimation method. |
|
|
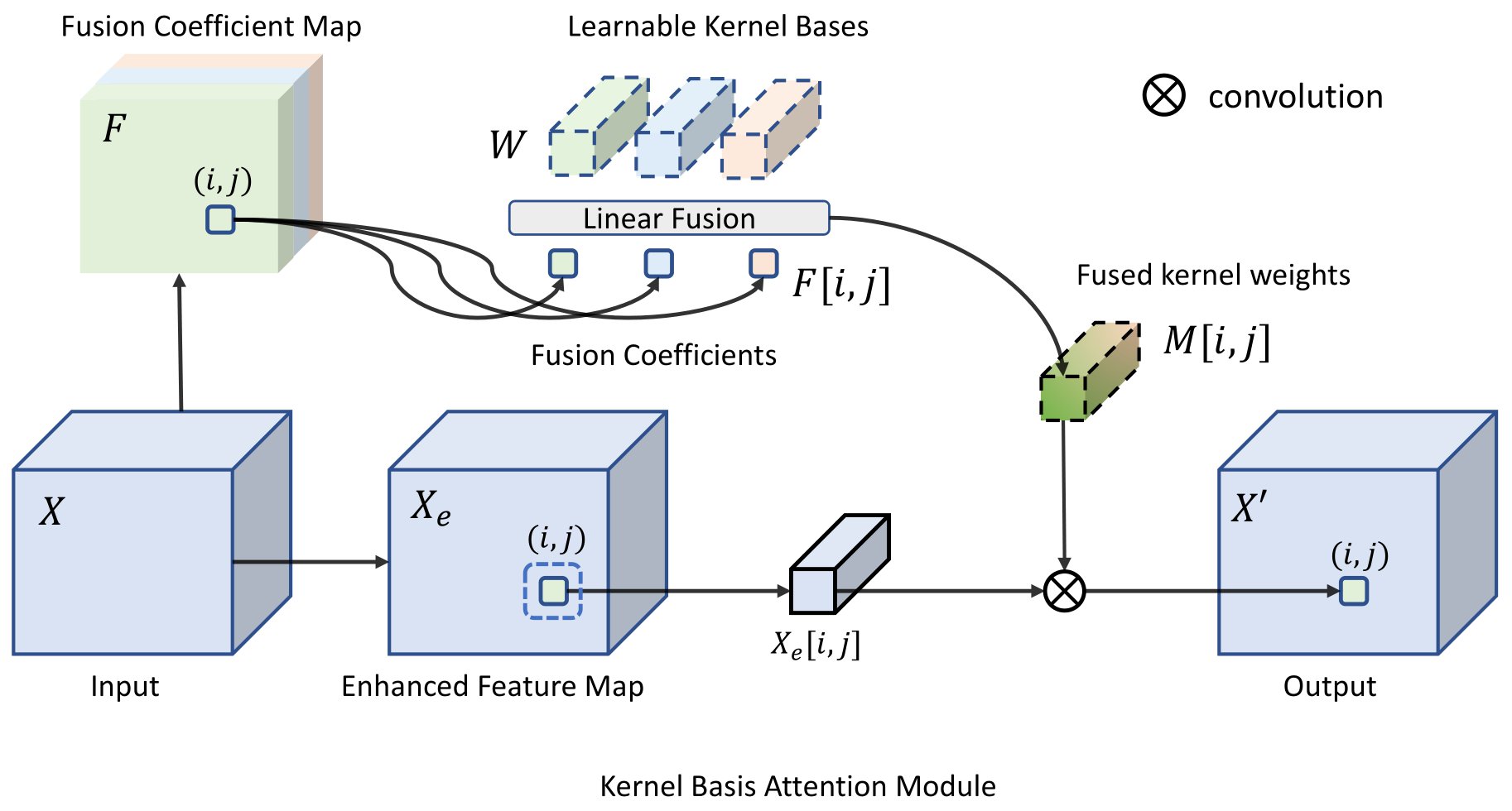
Yi Zhang, Dasong Li, Xiaoyu Shi, Dailan He, Kangning Song, Xiaogang Wang, Hongwei Qin, Hongsheng Li Arxiv, 2023 Paper / Code A general-purpose backbone for image restoration tasks. |
|
Xiaoyu Shi*, Zhaoyang Huang*, Dasong Li, Manyuan Zhang, Kachun Cheung, Simon See, Hongwei Qin, Jifeng Dai, Hongsheng Li CVPR, 2023 Paper / Code Ranks 1st on Sintel Optical Flow benchmark on Mar. 1st, 2023. |
|
|
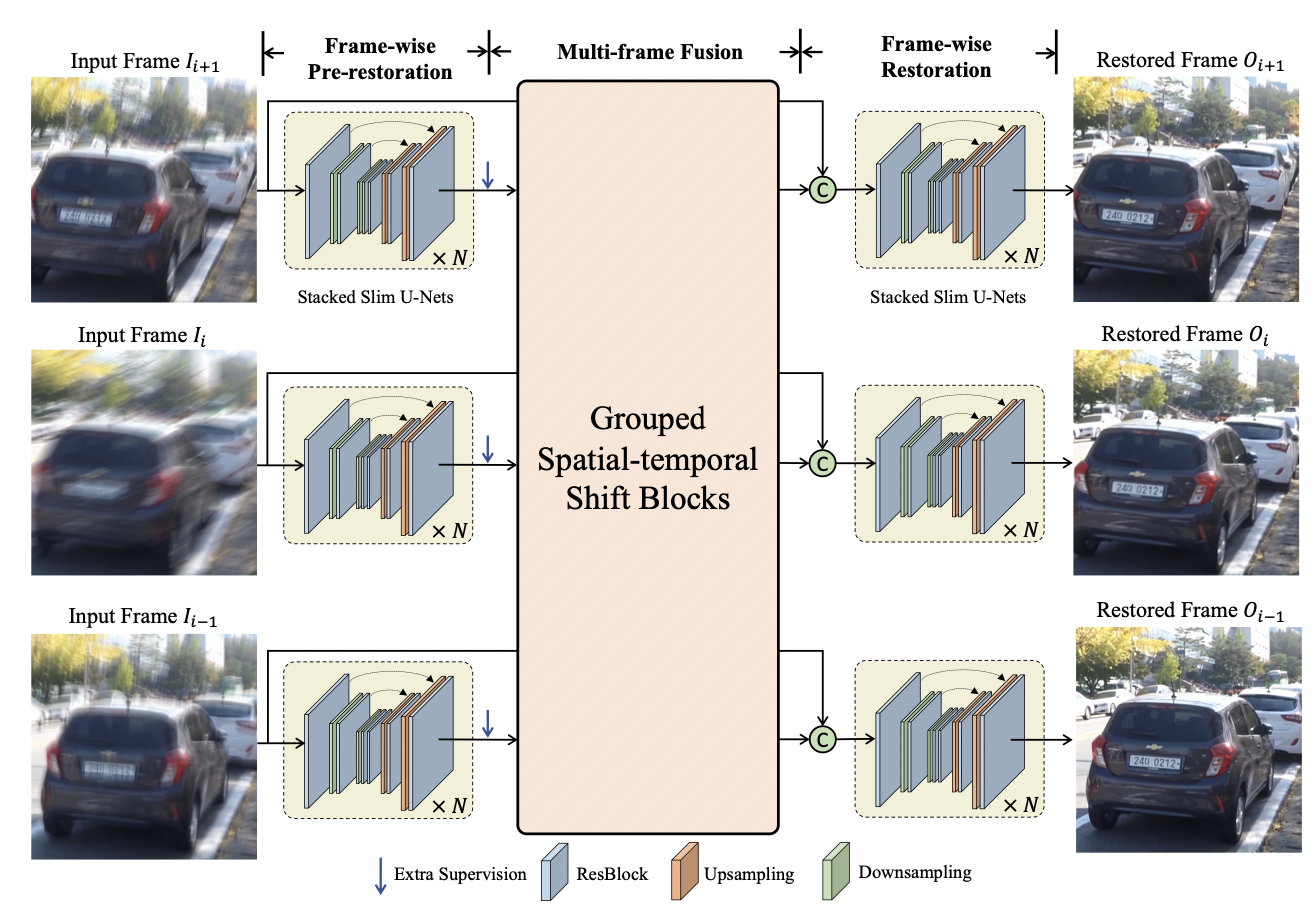
Dasong Li, Xiaoyu Shi, Yi Zhang, Kachun Cheung, Simon See, Xiaogang Wang, Hongwei Qin, Hongsheng Li CVPR, 2023 Project Page / Paper / Code Our approach is based on grouped spatial-temporal shift, which is a lightweight technique that can implicitly capture inter-frame correspondences for multi-frame aggregation. |
|
Zhaoyang Huang*, Xiaoyu Shi*, Chao Zhang, Qiang Wang, Kachun Cheung, Hongwei Qin, Jifeng Dai, Hongsheng Li ECCV, 2022 Project Page / Paper / Code Ranks 1st on Sintel Optical Flow benchmark on Mar. 17th, 2022. |
|
|
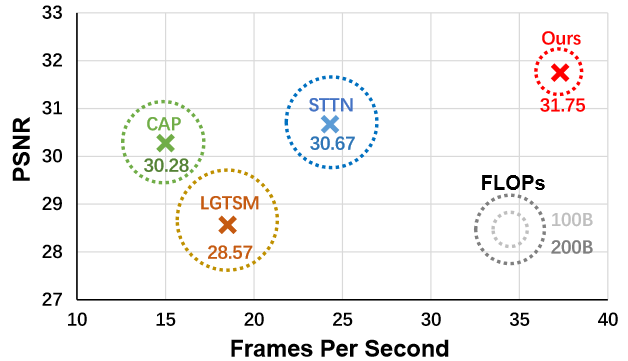
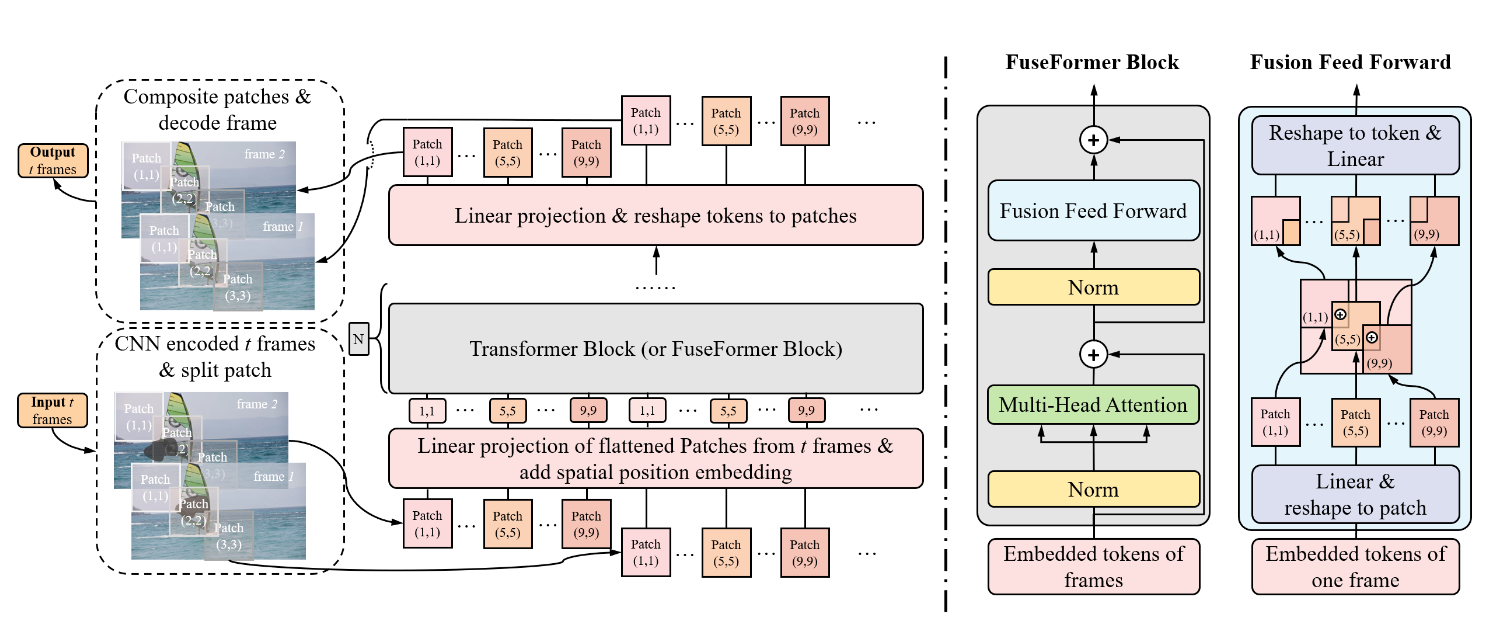
Rui Liu, Hanming Deng, Yangyi Huang, Xiaoyu Shi, Lewei Lu, Wenxiu Sun, Xiaogang Wang, Jifeng Dai, Hongsheng Li Arxiv, 2021 Paper / Code We propose a novel decoupled spatial-temporal Transformer (DSTT) framework for video inpainting to improve video inpainting quality with higher running efficiency. |
|
Rui Liu, Hanming Deng, Yangyi Huang, Xiaoyu Shi, Lewei Lu, Wenxiu Sun, Xiaogang Wang, Jifeng Dai, Hongsheng Li ICCV, 2021 Paper / Code A Transformer model designed for video inpainting via fine-grained feature fusion based on novel Soft Split and Soft Composition operations. |